Multidimensional Representation of Concepts as Cognitive Engrams in the Human Brain
D Marks, M Adineh, B Wang, S Gupta, J Udupa
Citation
D Marks, M Adineh, B Wang, S Gupta, J Udupa. Multidimensional Representation of Concepts as Cognitive Engrams in the Human Brain. The Internet Journal of Neurology. 2006 Volume 6 Number 1.
Abstract
Background
Although much information has been gathered concerning the storage and processing of information in the human brain, much remains unknown. Recent advances in neuroimaging have increased our understanding of human neuroanatomy (Prabhakaran 2000). Functional neuroimaging, particularly using Blood Oxygen Level Dependent (BOLD: Bandettini et al 1992) response of MRI (functional MRI, or fMRI), PET scans, Magneto-Encephalography, and other techniques have advanced our understanding of the brain's cognitive processing of information and memory (Rugg 2002; Binder 1999; Courtney 1998).
The study of cognition - the nature of various mental tasks and the processes that enable them to be performed - has made great conceptual advances. Herein is described a conceptual basis for cognitive processing, and a methodologic framework to understand how and where concepts (persons, places, objects, agendas, intents) are stored. For the purposes of this article, a Cognitive Engram (CE) refers to a representation of the three-dimensional region of the brain wherein neurophysiologic changes occur that reflect the function for storage and processing of specific memory elements / thoughts. In this paper, CEs are described, their significance is explored, and methods to monitor them are presented.
Methods
All research was conducted within an IRB-approved clinical protocol: “Use of Functional MR Imaging to Develop a Correlative Library of Activation Patterns Which Represent Visual Perception of Faces, H-002.”
Figure 1

Healthy adult volunteers, without exclusions to MRI scanning, were explained the study purpose and design, risks and benefits, given a chance to ask questions and then agreed to participate. The test subjects lay within a GE Cigna 3-T MRI scanner, wearing a phased array head coil, mounted with a 45-degree mirror, in a darkened room. This arrangement allowed test subjects to see images projected onto a rear projection screen positioned by their feet. Continual neuroimaging (fMRI) was performed during viewing of the test stimuli in order to capture structural and functional data. The data were analyzed for the presence of neuroimaging activation that has been shown to correspond to cognition and visual recognition. Test subjects were instructed to concentrate on the test images, including shape, unique features and familiarity.
Three sets of scans were performed per experiment: a short localizer scan was run first, to make sure that the field of view was within the skull, and to adjust out any “ghost images”. The localizer scan was followed by a full volume high resolution structural scan by using fast SPGR imaging (146, 1.0-mm thick axial slices, no spaces, TR = 8 msec, TE = 3.2 msec, FOV = 24 cm, 256 x 256 matrix). These T1-weighted images provided detailed anatomical information for registration and three-dimensional normalization to the Talairach and Tournoux atlas (1988), as described below.
Changes in the blood oxygen level dependent (BOLD) MRI signal were measured by using a gradient-echo echoplanar sequence. Functional MRI (fMRI) scans lasted 110 seconds each. EPI parameters were: TE 35 msec, TR 2000 msec, multiphase screen, 55 phases per location, interleaved, flip angle 90 °, delay after acquisition-minimum. By using a visual stimulus package, color photographs were presented in a mini-block design. In a typical session, after a 4 second lead-in time, a blank screen was displayed for 4 seconds, then the picture of interest for 4 seconds, blank, picture, repeating for the scan time.
Data Analysis
Analysis of Individual fMRI Experiments
The fMRI scan volumes were motion-corrected and spatially smoothed in-plane. MRI data files were normalized and analyzed by using MedX to compute statistical contrasts and to create a spatial map representing significantly activated areas of the brain that responded differentially to the seven individual visual test stimuli. We employed a conventional analysis of data (as opposed to multi voxel pattern analysis, described later). For the voxels which show an overall increase in activity for meaningful stimuli, a positive regression analysis for the contrast between a test photo and control (blank screen) stimuli was conducted. This created an activation map containing specific voxels with an uncorrected probability of P ≤ 0.05, meaning every voxel showed activation with the probability greater than 0.95. Only these voxels were selected for further analysis.
This statistical map was then superimposed on coplanar high-resolution structural images. The partial volume structural images were registered with the full volume high-resolution images by using Automated Image Registration (Woods, Mazziotta & Cherry, 1993). The full volume high-resolution images were then transformed (registered and normalized) to the Talairach and Tournoux atlas (1988) by using MedX tools. Each activated voxel on these images was selected to obtain Talairach (X, Y, Z) coordinates of brain regions that responded maximally to the test stimuli and to further generate a CE. We constructed three-dimensional representations of the activated areas, as bubble point representations of the brain activation points (DPlot, HydeSoft Computing, Vicksburg, MS).
Group Analysis by Using SPM
Similar groups of imaging runs were also analyzed as groups (i.e. all imaging runs for the bloody knife), using a 2 step-analysis.
Results
Application of Cognitive Engrams to Individual Faces
Functional MRI experiments were performed on normal volunteers, while they viewed color test images (Saddam Hussein n=8, Pres. Bush n=8, Osama Bin Laden n=6, El Zarquari n=6, Silvio Burlosconi n=4, a handgun n=8, and a bloody knife n=8). Activation points for viewing each specific test figure were pooled across individuals, yielding a consensus set of activation points across test subjects for each specific test photo (a conventional analysis). Only voxels which were present in 80% or more of the individuals viewing a particular photo were included in the consensus data sets (Figures 1-7). The specific areas of the brain, which were activated, are described in Table 2. Across individuals, a wide selection of brain regions are activated during recognition of specific objects.
Figure 2

Figure 3

Figure 4

Figure 5

Figure 6

Figure 7

Figure 8

Legend
Figures 1-7 show scatter plots (dPlot) of common groups of data across individual viewers when viewing the corresponding test images (shown superimposed on the Analyze maps). Representative cuts from the consensus Analyze maps are also shown. Across test subjects, there appears to be a specific pattern of activation corresponding to each of the individual test faces (5) and objects (2). These patterns of activation varied between test images, allowing a correlative distinction to be made.
Figure 9
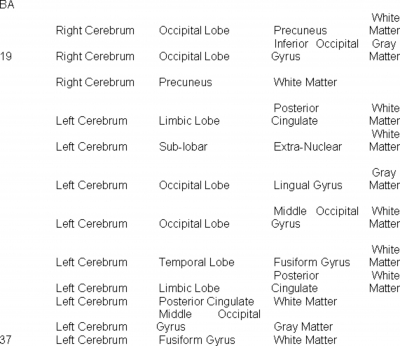
Table 2 shows that there is a wide set of locations of brain activation when viewing specific faces. The activation extends way beyond the fusiform gyrus, and includes areas involved with vision, emotion and memory.
Discussion
We have shown that, across individuals, when a color photo of a specific human face or object is viewed, a corresponding and unique distributed pattern of activation occurs in the human brain. Different male faces and objects induce distinctively different activation patterns, allowing the determination of which test face or object a test subject viewed by comparing its activation pattern to a library of consensus activation patterns.
Certainly, a variety of factors will influence the process of recognition, including familiarity, culture, emotional response, viewing conditions, and context and clarify of presentation. Although all test subjects recognized test images 1,2,4,6,7 there was no recognition of test images 3 and 5. Yes, regardless of recognition, consistent patterns of brain activation were formed. This indicated that the formation of consistent patterns of brain activation (Cognitive Engrams) is a general quality across individuals, and not dependent on recognition.
One application of the concept of CEs that our lab is pursuing is a form of applied “mind reading.” By observing the pattern of activation for different objects, an atlas of activation maps – a veritable Rosetta Stone of the mind - can be constructed that could allow the determination of what is being viewed by analysis of the activation map created. With current technology, requiring long imaging sessions in a large and expensive instrument (MRI) this is prohibitive in other than a research surrounding. As for all technology (for example the cell phone and PC), reductions in size and cost along with increases in resolution and speed can be expected. We anticipate the eventual development of a walk-thru or perhaps even a remote fMRI scanner, allowing a rapid (possibly even surreptitious) fMRI to be taken, allowing the interpretation of thoughts on an active basis.
The method by which the brain identifies and remembers a specific face is the subject of much discussion and conjecture. A critical area of image processing is the fusiform face area (FFA), a subset of the fusiform gyrus, in the medial temporal lobe (MTL). fMRI studies have been very useful in understanding the role of various anatomic areas in recognition of the face and other objects.
Ishai et al (1999, 2000) studied the representation of objects in the human occipital and temporal cortex by using fMRI. They found three bilateral regions in the ventral temporal cortex (VTC) that responded preferentially to standard stick images, faces, houses, and chairs. Rather than activating discrete, segregated areas, Ishai et al found that each category was associated with its own differential pattern of response across a broad expanse of cortex. To investigate these findings further, they evaluated the distributed patterns of response to these standard objects with passive viewing, delayed matching, and varied presentation formats (photographs, line drawings). However, they did not study the different activation patterns between specific faces, as opposed to faces in general.
The representation of objects in the ventral visual pathway, including both occipital and temporal regions, did not seem to be restricted to small, highly selective patches of cortex but, instead, was a distributed representation of information about object form, much as we have determined for faces and objects. By using activation coordinates supplied by Ishai et al, three-dimensional constructions of their data sets were prepared (data not shown). The pattern for each object category (face, chair, house) was distinguishable, and the patterns of photos of an object were distinguishable from that of the outline of the same object, by using a similar method of analysis to that for our own data, presented herein. This implies that the two variations of memory storage of similar visual representations of similar objects are done differently, and can be discerned by the differences in their activation map patterns.
We observed differences in the locations for activation in our own data from that of Ishai et al. This may be due to study design, and in particular to the use of color photos of faces, rather than morphed or stick figures.
Haxby et al (200,2001) used fMRI to investigate the functional architecture of the object vision pathway in the human brain. Patterns of response were measured in the Ventral Temporal Cortex (VTC) while subjects viewed faces, cats, five categories of man-made objects (bottles, scissors, shoes, and chairs), and nonsense pictures. They reported that a distinct pattern of response could be discerned for each stimulus category. Unfortunately, the activation maps or individual coordinates of hot spots were not provided to allow for an independent graphical symbolic reconstruction.
Thus, Ishai, Haxby and other researchers have determined that information encoding faces and various objects is present in multiple brain regions, some of which are overlapping. In this “object form topography” model, the VTC has a topographically organized representation of attributes of form that underlie face and object recognition. The representation of a face or object is reflected by a distinct pattern of response across a wide expanse of cortex in which both large- and small-amplitude responses carry information about object appearance.
We have created three-dimensional models of activation (data not presented) for generalized faces, chairs and houses, based upon data for activation coordinates published by Ishai et al, 2000 and others. These 3-D representations appear to form a prototypic or generic representation of the actual conceptualization of the object (face, chair, house) being viewed. Our CE concept may have some analogy, though on a much more detailed scale, to object form topography. In the case of CE though, the topographical representation is not restricted to the VTC, but is expanded to the whole brain. Further, a unique 3-D shape and structure are imparted to the CE, which was not noted for object form topography. To some extent, this concept has been approached by Haxby et al (2000, 2001) for the activation pattern in the VTC. As opposed to our work reported herein, Haxby et al did not formulate their analysis of activation patterns into three-dimensional correlates of object representation, nor did their analysis appear to cover areas of the brain outside of the VTC.
A number of observations can be made of the CEs we prepared, derived from the data of Ishai et al (1999 and 2000) and others. First, the three-dimensional outlines of the activation points for these generalized visual concepts (generic face, chair, house) are dissimilar and unique from each other. The differences appear marked enough to be able to identify or distinguish one pattern (face, chair or house) from another, and these differences may allow one to go in the reverse direction, from a library of unique CEs to identify the object being imaged. These findings support our conclusions concerning Cognitive Engrams.
Na et al (2000) assessed activated brain areas during the stimulation task of item recognition, followed by an activation period. They observed that the prefrontal cortex and secondary visual cortex were activated bilaterally by both verbal and visual working memory tasks, and the patterns of activated signals were similar in both tasks. The authors speculated that bilateral prefrontal and superior parietal cortices activated by the visual working memory task may be related to the visual maintenance of objects, representing visual working memory. We are studying Cognitive Engrams for both recognized and unrecognized visual stimuli, and their patterns of persistence with time.
Bernard et al recorded data activation areas when viewing famous and non-famous faces. They noted distinct activation map patterns for famous as contrasted to non-famous faces, analogous to the familiar and non-familiar faces of our own studies. Rather than viewing a face, and then observing the activation pattern, out hypothesis is that it is possible to view the activation pattern and determine what the individual was viewing. We compared the activation map data from the second experiment of Ishai et al (2000) viewing morphed faces, to data from Bernard et al (2004) non-famous face, expecting to see activation maps similar in structure, but did not (data not shown). The differences seen between the CEs could be explained by experimental design, imaging technique, or dissimilarities in the faces themselves. Regardless, the data regenerated from Bernard et al into CEs demonstrate the potential to determine whether specific faces are recognizable, and whether they are famous or non-famous.
Note that Ishai's (2000) experiment 2 used one distinct facial photograph, whereas the data of Bernard represent an amalgam of representations of 20 different faces. Unfortunately, Bernard's data on activation maps for the individual faces was not, to out knowledge, made publicly available to the scientific community. It is unfortunate that more experimental imaging data is not made openly available for analysis by the scientific community. In fact, such an open disclosure of imaging data is encouraged as a condition of government funding support:
(http://grants.nih.gov/grants/policy/data_sharing/data_sharing_guidance.htm). Academic structures which facilitate sharing of fMRI data do exist (
The fusiform face area (FFA) is known to be central in processing the perception and recognition of faces (Kanwisher et al.). There are two models on the breath of brain activation, which takes place during visual recognition. The widely distributed model, as supported by data from this paper, and of Ishai and of Haxby, indicate that visual recognition involves a number of anatomically disparate but functionally collaborative regions of the brain. Using morphed faces of famous individuals, Rotshtein et al. (2005) argued for an identity-based representation of faces in the FFA, with neurons showing categorical tuning for different individuals. Their data supported a hierarchical model of face perception. Rotshtein et al divided facial discrimination into components of physical and identity differences, and showed that processing takes place in the inferior occipital gyrus (IOG) and right fusiform gyrus (FFG) respectively. They also determined that the bilateral anterior temporal regions showed sensitivity to identity change that varies with the subjects' pre-experimental familiarity with the faces, an area that we are studying using our own system.
Another study has posited a model of face representation in the FFA in which individual faces are encoded in a global face space by their direction (facial identity) and distance (distinctiveness) from a ‘mean'‘ face (Loffler et al.). When facial geometry (head shape, hair line, internal feature size and placement) was varied, the fMRI signal increased with increasing distance from the mean face. Furthermore, adaptation of the fMRI signal showed that the same neural population responds to faces falling along single identity axes within this space. These results suggest an invariant, sparse and explicit code, which might be important in the transformation of complex visual percepts into long-term and more abstract memories. Certainly, Loffler's model is consistent with Cognitive Engrams.
Interestingly, Quiroga et al (2005) identified a small subset of neurons in the MTL that are selectively activated by different pictures of given individuals, landmarks or objects and written names. The findings do not mean that a particular person or object is recognized and remembered by a restricted number of brain cells. Nor do they mean that a given brain cell will react to only one person or object, because the study participants were tested with only a relatively limited number of pictures, as were those in our own study. In fact, some cells were found to respond to more than one person, or to a person and an object. Yet, Quiroga et al concluded that the brain appears to use relatively few cells rather than a large network to record visual stimulation. How these findings relate to the concept of Cognitive Engrams will be developed. The results we present are more consistent with a sparse but widely spaced code, involving a number of different locations in the brain, and which appears to be uniform across individuals.
As imaging resolution improves, more detailed maps will be produced, hopefully representing individual neural activation and less simply a regional activation. One method to improve imaging detail will be by applying greater magnetic field strength, as has occurred with movement from 1.5 T to 3.0 T MRI units. A second improvement will occur when all voxels exhibiting activation are included individually rather than as clusters in analysis for CE patterns. For purposes of analogy, data for files are often stored on computer hard drives in discontinuous segments, but are considered as one because the computer keeps track of the individual data segment locations. Similarly, it may be an error to not consider small (not cluster) activation areas on fMRI (now removed by statistical smoothing), because such smaller areas may represent important components of storage of individual concepts. Smaller activation areas may represent finer points of differentiation between general “faces” and individual faces.
We are in the process of increasing the number of volunteers imaged per visual stimulus to supplement the consensus activation point sets. This should increase the resolution, and allow the application of multi-voxel pattern analysis (MVPA: Edelman; Friston; McIntosk; Haxby 2001; Sidtis) to the image sets. The MVPA approach should led to a number of advances, including capture of resolution which was lost with data smoothing (Kriegeskorte), and inclusion of all activated voxels, which should also increase the resolution. The goal should be to increase resolution by decreasing voxel size toward that of individual neurons.
Increasing our data sets will also allow for a determination of demographic influences (age, sex, cultural background, political orientation, language, recognition) on activation patterns. Certainly these factors will have an influence on how objects are perceived, but may show up more in brain areas associated with emotional response than with object recognition.
We have embarked on a three-prong approach to develop our cognitive imaging data sets. First, as we image an increasing number of faces and objects, we are developing a Rosetta Stone-like library of corresponding consensus activation patterns, which we have termed Cognitive Engrams. Second, by analyzing the data bi-directionally, we expect to allow more fluid and on-line “mind reading” of the individuals being imaged. Third, we are increasing the resolution of our data sets by using a 3T magnet, moving from 64x64 to 128x128 and soon to a 256x256 grid, increasing our computer processing power and software to accommodate as detailed an MVPA of all voxels (not just clusters) as possible (Sayres 2005), and investigating ways to quantify the intensity of a voxel rather than just its on or off state.
Conclusions
We have presented new imaging data that confirm and extend the conceptual interpretations of past authors in the area of visual recognition. We were able to produce experimental activation maps that were similar in some respects to imaging of drawings of generalized faces seen by Ishai et al (1999 and 2000). Our results for identification of fMRI patterns for general face recognition are consistent and extend prior work by Ishai, Haxby and others.
We have shown that for the first five faces and two objects we have studied; unique fMRI patters – Cognitive Engrams - are generated, allowing one to distinguish individual faces from the activation maps. We anticipate that this activation map library will form the basis of a Rosetta Stone, which will allow one to go from activation pattern to determine what (face, place, object, intent) was viewed.
Potential uses / applications of this Rosetta technology we have been exploring include the development of research tools for developing a deeper understanding of storage of visual objects in the brain. We are adapting our techniques to forensic applications including interrogation, looking for CE of specific faces, places, items, intents during national security and criminal investigations. CE can be applied to pharmacology research, for example looking for central nervous system therapeutic or adverse effects of various medications.
As the voxel size is further reduced, identification of individual cells and even subcellular areas of activation will be identified. It is conceivable that individual cells representing critical areas of a cognitive engram for an unwanted memory may have their activation state changed, through repolarization, inactivation / directed cell death, or modified in other ways. This may have the ability to modify (erase, create, modify) an individual memory. Concurrent with the development of these application areas, scientists must remain aware of the ethical implications of this work, and to avoid uses, which diminish or demean an individual's dignity and privacy.
Acknowledgements
We are grateful to St. Vincent's Hospital in Birmingham, Alabama for the generous use of their 3T MRI imaging time, and to Cooper Green Mercy Hospital for use of their clinical facilities.